搜索树数据结构支持很多动态集合操作,如search(查找)、minmum(最小元素)、maxmum(最大元素)、predecessor(前驱)、successor(后继)、insert(插入)、delete(删除)。这些都是基本操作,能够使用一颗搜索树当做一个字典或者一个优先队列。
12.1、什么事二叉搜索树
二叉搜索树是以一棵二叉树来组织的,能够用一个链表数据结构来表示,也叫二叉排序树、二叉查找树。当中的每一个结点都是一个对象,每一个对象含有多个属性(key:该结点代表的值大小。卫星数据:不清楚,left:左孩子结点,right:右孩子结点,p:双亲,貌似是单亲)。
假设某个孩子结点和父结点不存在,则对应属性值为NULL;
根结点是树中唯一父指针为NULL的结点。
二叉搜索树的性质:
设x是二叉搜索树中的一个结点。若y是x左子树中的一个结点,则y.key <= x.key;若y是x右子树中的一个结点,则y.key >= x.key;
通俗讲就是二叉搜索树中的随意一个结点的做孩子结点值不大于该结点,右孩子结点的值不小于改结点。
二叉搜索树的keyword都是依照二叉搜索树性质的方式存储的。即仅仅要一个数是二叉搜索树,则必须满足上述性质。
不同的二叉搜索树能够代表同一组值的集合。
二叉搜索树的性质同意我们通过一个简单递归算法来按序输出二叉搜索树中的全部keyword(遍历时,从根结点開始遍历),依据递归时子树根的keyword与其左右子树keyword输出顺序的不同,分三种便利方式:
若递归遍历时输出的子树根的keyword位于其左子树的keyword和右子树的关键之间,则称为中序遍历。
若递归遍历时输出的子树根的keyword位于其左子树的keyword和右子树的关键之前,则称为先序遍历。
若递归遍历时输出的子树根的keyword位于其左子树的keyword和右子树的关键之后。则称为后序遍历。
中序遍历的简单递归过程为:
middleOrder (x){
if(x != null)
middleOrder (x.left);
print x.key;
middleOrder (x.right);
}
先序遍历的简单递归过程为:
preOrder (x){
if(x != null)
print x.key;
preOrder (x.left);
preOrder (x.right);
}中序遍历的简单递归过程为:
afterOrder (x){
if(x != null)
afterOrder (x.left);
afterOrder (x.right);
print x.key;
}举比例如以下图:

中序遍历分析:
1、依据中序递归的运行过程。可推断从最左下方開始输出。2,5(6的左孩子的keyword,此时为子树根),5,这三个数各自是左孩子,子树根。右孩子,依照中序遍历的定义,则输出顺序为2、5(子树根)、5(右孩子)
2、5、6、7三个类似。输出5、6、7
3、7无左孩子。则直接输出7、8
最后结果为:2、5(6的左孩子的keyword)、5(6的左孩子的右孩子)、6、7、8
先序遍历方式为:依据先序递归的过程,先输出子树根结点。再递归遍历其左子树和右子树结点,结果为:6、5(6的左孩子)、2、5(6的左孩子的右孩子)、7、8
后序遍历方式为:依据后序递归的过程,先输出子树根的左右结点,再输出子树根结点,结果为:2、5(6的左孩子的右孩子)、5、5(6的左孩子)、8、7、6
关键点:可想象递归程序的运行过程,来推断输出结果。
定理:假设x是一棵有n个结点子树的根,那么调用middleOrder(x)须要Θ(n)时间,同理preOrder和afterOrder也是Θ(n)时间。
定理分析:证明该递归算法须要Θ(n)时间,则须要证明Ω(n)<=T(n)<=Ο(n)
遍历单个结点时间如果为常量,则由于须要遍历n个结点,所以T(n)>= Ω(n)。即最少须要时间为n的线性函数,系数和常数项省略,Ω简单说表示所需时间的下界。
T(n)<=Ο(n)证明省略。
练习:
12.1-1 对于keyword集合{1、4、5、10、16、17、21},分别画出高度为2、3、4、5、6的二叉搜索树。
分析:例如以下图:
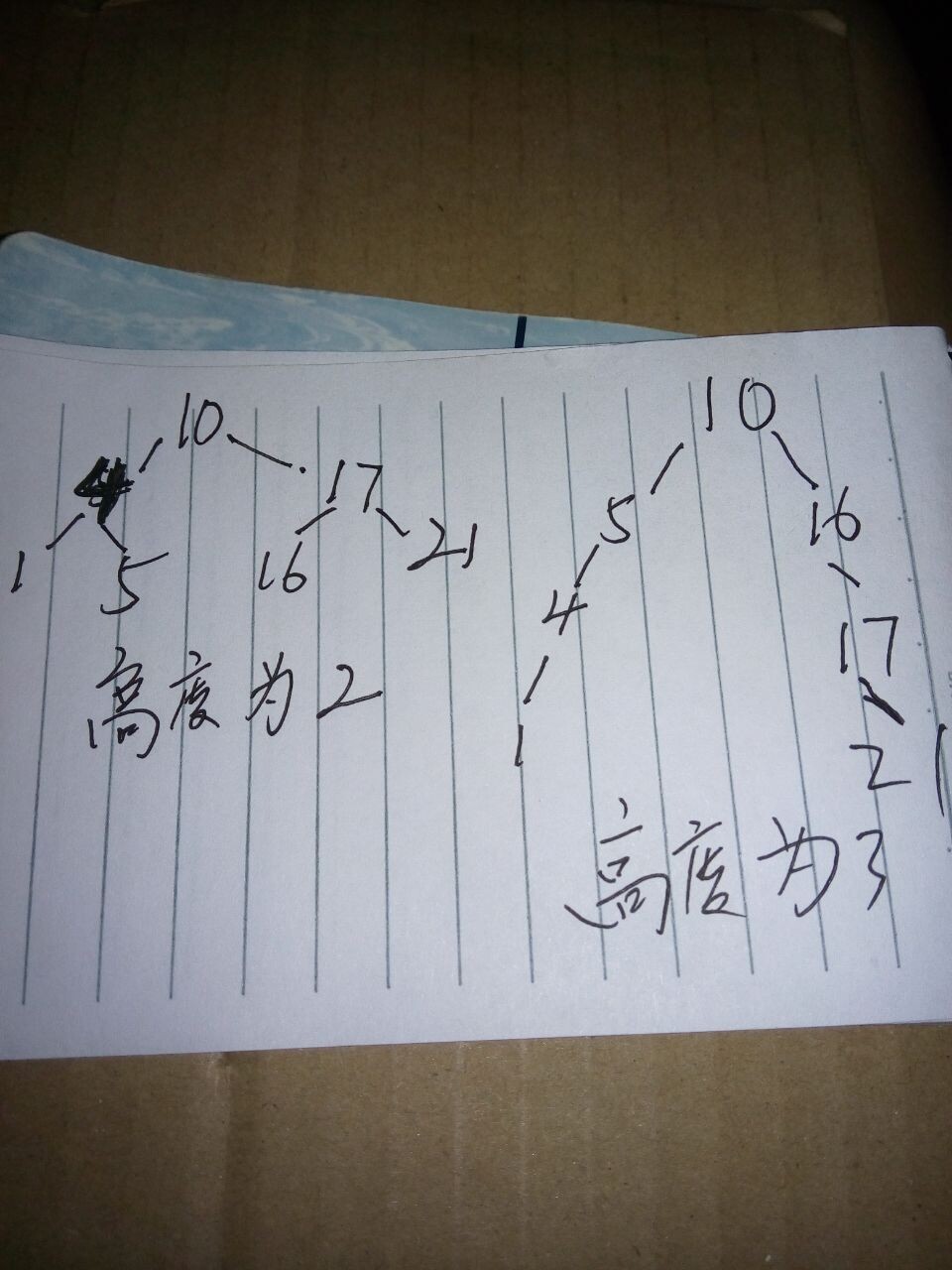


2、待续。